
Rule of Large Numbers in Election Results
CitizensOversight (2019-03-08) RayLutz
This Page:
copswiki.org/Common/M1890
More Info: ElectionIntegrity
Recently, I have read a number of documents that claim to have detected likely fraud in an election because the results did not comply with the "law of large numbers (LLN)." For example, we have this recent article on "soapboxie" that claims that the cumulative average indicates that the 2004 election in Ohio between John Kerry and George W. Bush may have been hacked:
As you will see, these analyses are unreliable and generally provide no information about any likely fraud.
The reason the LLN does not apply is because it only applies to random events, and the order in which precincts are generally processed in any election is not truly random.
You can read about the general Law of Large Numbers in this Wikipedia article: https://en.wikipedia.org/wiki/Law_of_large_numbers
They provide this example of the average of dice rolls, which is a truly random event. The cumulative average provides the typical form of the curve as each roll is added to the sum. You will note that at first, the average can wiggle quite a bit, and then it settles out to the average.
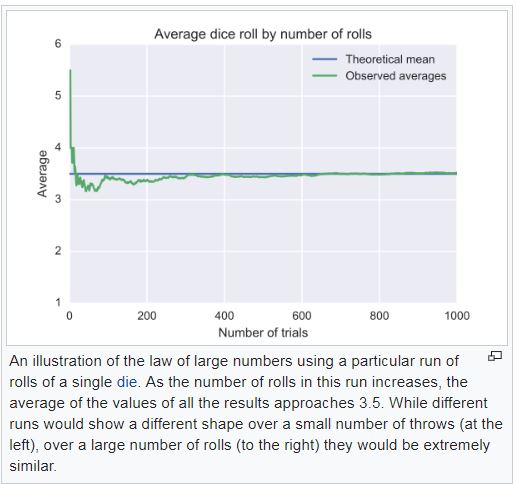
In election districts, however, the results are typically formed by including votes precinct by precinct. The precincts are typically defined geographically, and there can be a fairly wide distribution over the various precincts.
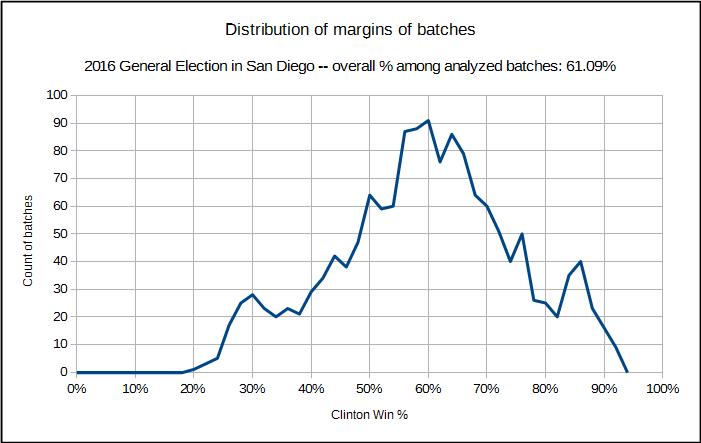
We will take an actual example of the election results in San Diego County in the November 2016 general election for only the two major party presidential candidates, Clinton and Trump, and including only the precinct results and not results that were not allocated to the precincts. In San Diego, there were 1552 precincts, and we will note that the distribution of the margin of victory for Clinton over Trump varied widely, as can be seen in the following diagram showing the distribution of the precincts in terms of the margin of victory for Clinton (and the margin for Trump would be 100% minus Clintons margin.)
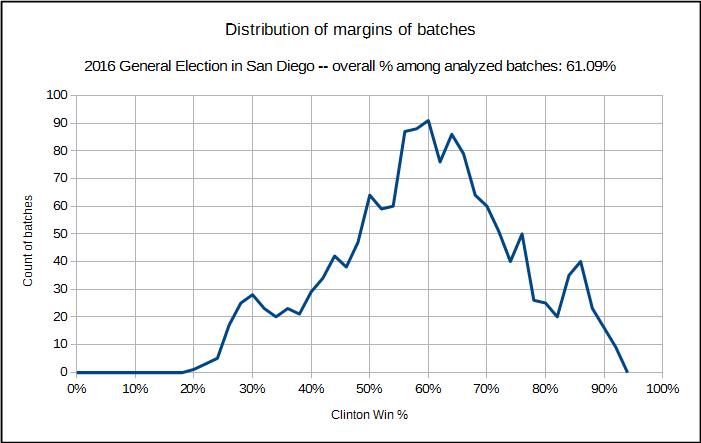
We can see in that diagram that there are three notable humps, one hump where there were quite a number of precincts where Clinton did poorly, one where she did very well, and then the largest in the middle where it was generally like the final result of 60%. The order in which these are processed is very important.
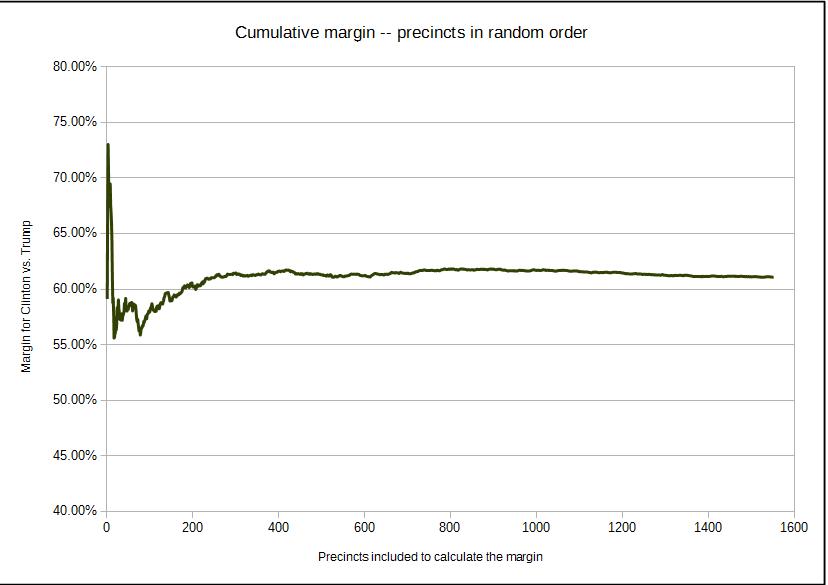
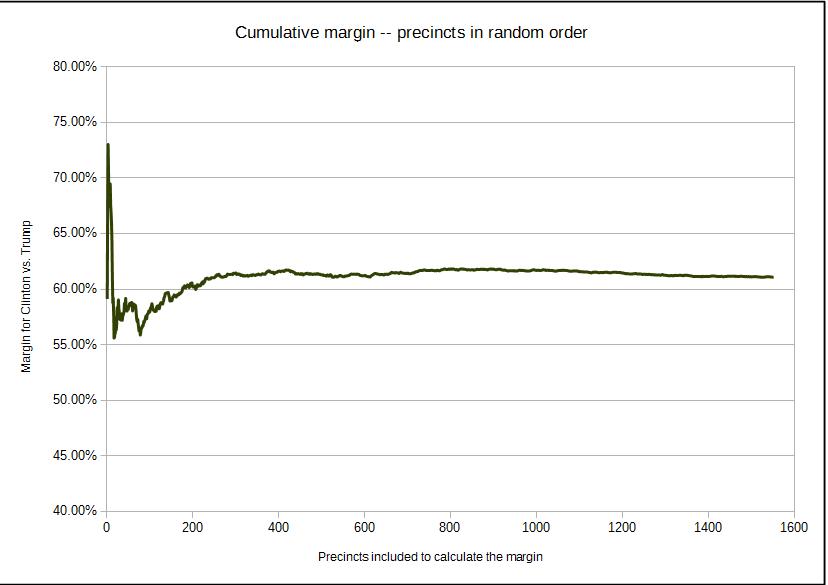
If we draw the precincts at random, then we will get the typical curve as we expect from the LLN.
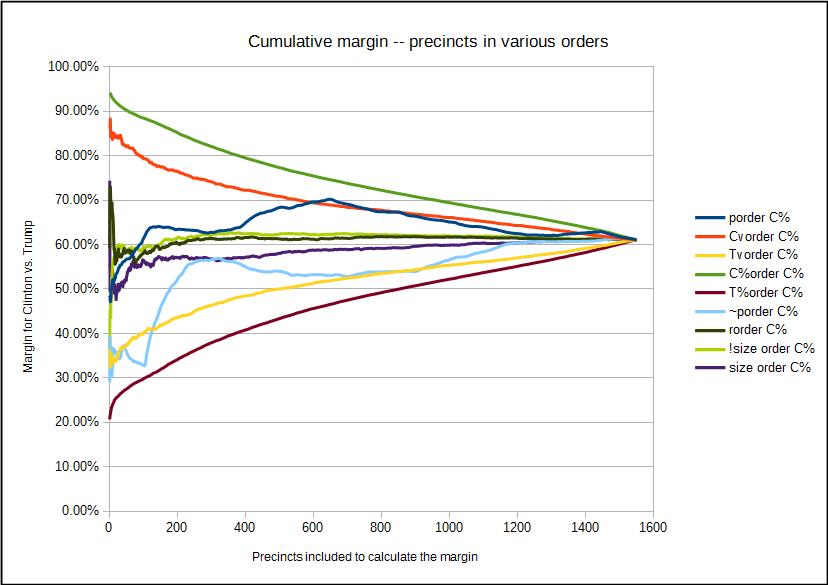
But if we take the precincts in various orders, then the results are far different, as can be seen below:
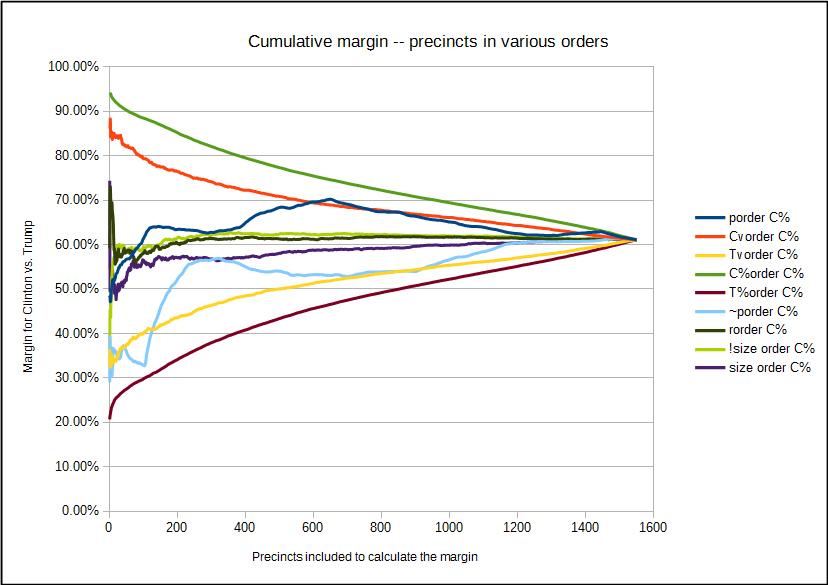
The maximum envelope provided by the top curve and the bottom curve is obtained if the precincts are sorted by the margin for Clinton (light green) or for Trump (violet), and then form the cumulative average. Nothing can ever exceed these bounds.
The next curves "in" from the top and bottom curves provides the result if we sort the precincts by raw maximum vote count for Clinton, from most to least (red) or for Trump (yellow). These are not the same because in a large precinct, the vote count for Clinton might be large, but still smaller than that for Trump, and so this curve will be a bit closer to the true average.
The dark blue curve and the light blue curves provides the cumulative average when the precincts are processed in the official sequence and in reverse. All these would look "suspicous" by many writers, but the wide variation is due not to changing the election, but just changing the order in which the precincts are included in the cumulative average.
The Dark Green curve is the result when the precincts are sampled randomly, as provided earlier.
Many of the analyses of such cumulative margins runs from large precincts to smaller precincts or the reverse. It all depends on how they are distributed. In this plot, if the cumulative sum is performd from large precincts to smaller precincts, that is the very light green curve which is most like the randomly sampled precincts curve (dark green), and when performed from small precincts to large precincts, we get the purple curve.
In this case, using the total size of the precinct in votes cast is the closest to mimicing the random selection IN THIS CASE but in other election districts, the size of the districte just might be correlated with precincts that will vote for one candidate vs. another.
Thus, those who attempt to analyze the trends of the cumulative sum when the precincts are not sampled randomly should not be surprised by the sort of wiggling of the curves you see here, and it does not mean the election has been hacked. Indeed the various curves you see here are for the SAME election results simply processed in different orders.
This is NOT a reliable approach from a statistical standpoint to detect election hacking or manipulation.
--Ray Lutz
{kind=link}
{kind=link}
{kind=link}